

Table of Contents
MQSeries Techniques
- Queue Choice
- Message Class
- Waiting for Messages
- Automatically starting MQSeries programs
- Unit Of Work Size
- Example programs
Queue choice
For any MQSeries application you need to decide what MQSeries queues to use, and which classes of message you require. It is recommended that applications are not written with hard coded queue or queue manager names, but instead utilise a runtime configuration mechanism, perhaps a simple text file, that contains this information that is read each time the application is started. This enables a degree of dynamism in the queue selection for an application.
Message class
Most applications will require that their communications are assured. This means that the messages sent must be classed as persistent. There are 2 ways in which this can be achieved:
- explicitly set message persistence when putting the message onto the queue by using the MQPER_PERSISTENT named constant in the Persistence field of the message descriptor structure
- when defining the queue that the message is put on to first, set the default persistence attribute, DEFPSIST, to YES, and then use the MQPER_PERSISTENCE_AS_Q_DEF named constant in the Persistence field of the message descriptor structure when putting the message

When a queue manager is routing a message from the source queue to the destination queue, irrespective of locality, it moves the message maintaining its persistence state. This means that the first time a message is put onto a queue its persistence state is defined. The state remains unchanged regardless of the value of the DEFPSIST queue attribute of any intermediate queue that the queue manager may need to place the message on during the routing process.
The recommended method is to use method 2 above as this does not set the message class in the application program code.
Setting the class of messages to persistent will detrimentally affect the overall performance of the application, as messages of this class are backed by hard disk storage while they remain on a queue. It is the read and writing of the disk storage that takes the extra time. The loss of performance is however very small.
Waiting for messages
A program that is servicing an MQSeries queue can await messages by:
- Making periodic calls on the queue to see whether a message has arrived
- Waiting until either a message arrives, or a specified time interval expires
The method chosen will depend on the requirements of the application. The same MQI call is used in either case, namely MQGET, only the parameters change. It is the get-message options structure that controls whether a call to MQGET will wait for a message to arrive, or return immediately indicating whether a message was found.
An application program can only wait for messages on one queue at a time. This implies that, if a program must service more than one queue, it will have to use the queue polling technique.
Message matching criteria
Every message carries with it a message identifier in its control data section, specifically the MsgId field of the message descriptor structure. This field can either be filled in when the message is put onto a queue by an application program, or automatically filled in by the queue manager at the request of the application program. The program requests the queue manager to generate the field value by filling it in with the named constant MQMI_NONE.
The queue manager generated value is guaranteed to be unique to that message, whereas the program supplied value can be anything required, constrained only by the size and data type of the field. A second field, CorrelId, is also available to the program to provide additional data, and is left as-is by the queue manager.
When getting a message from a queue it is possible to instruct the MQGET call to try to get a particular message. This is achieved by using the MsgId and/or CorrelId fields of the passed message descriptor structure to define the values that will cause a successful match.
Correlating replies
In MQSeries applications, when a program receives a message that requests it to do some work, the program will usually send one or more reply messages to the requester. To help the requester to associate these replies with its original request, application programs can use the CorrelId field in the message descriptor section of messages. Programs should copy the value of the MsgId field of the request message into the CorrelId field of the reply message.

The MsgId is also available to the requesting program as a return value from MQPUT or MQPUT1, therefore it can be used as the matching criteria by the requesting program in an MQGET call to await a specific reply message. It can be seen then, that by using a combination of the MsgId and CorrelId fields, an application can send a request and await the reply for it. However, it is considered bad practice to operate synchronously, that is, send a request message, wait for the reply, send another request, wait for that reply, and so on.
It is more efficient to operate asynchronously, that is, send all the requests, one after the other, and then await the replies, one after the other. This allows the receiving program to start working on the first request at the same time as the requesting program is generating the requests that follow.
Automatically starting MQSeries programs
The queue manager defines certain conditions as constituting trigger events. If triggering is enabled for a queue and a trigger event occurs, the queue manager sends a trigger message to a queue called an initiation queue. The presence of the trigger message on the initiation queue indicates that a trigger event has occurred.
A program is required to service the initiation queue, it is known as the trigger manager, and its function is to read the trigger messages and take the appropriate action. Normally this action would be to start some other program to service the queue that caused the trigger message to be generated. As far as MQSeries is concerned the trigger manager is just another application program, and the initiation queue is just another queue.
If triggering is enabled for a queue, that queue must have associated with it a process definition object. This object contains information about the application program that is to be started to process the message that caused the trigger event. When the queue manager generates the trigger message it reads the information in the process definition object and places it in the trigger message, for use by the trigger manager. Each triggered queue can have its own process definition object.
A trigger message can be generated for a queue:
- Every time a message arrives on the queue
- When the first message arrives on the queue
- When the number of messages on the queue reaches a predefined number
These conditions are controlled by queue trigger attributes whose values can be set either by using MQSeries commands, or programmatically using the MQINQ and MQSET MQI calls.
It is inefficient under most circumstances to generate a trigger message every time a normal message arrives on a queue. If however the messages are very infrequent this approach would be the most efficient use of the available resources.
The arrival of a message on a triggered queue starts a chain of events as shown below.
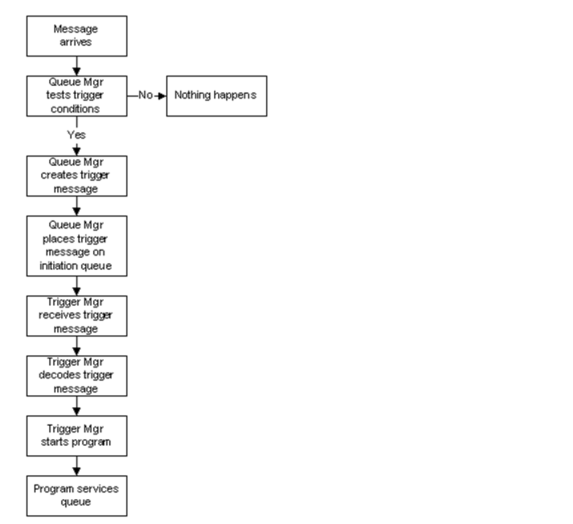
As can be seen from the above diagram starting a triggered program is fairly complicated, and involves several discrete steps and MQSeries objects. Once set up however, triggering works without further interaction.
As soon as a program has been started by the trigger manager it is recommended that the program should temporarily disable triggering on the queue, using the MQSET call, to stop any further programs from being started. The program should ideally process all the messages on the queue, and then wait a given amount of time for any further messages to arrive before finishing. When the program has finished all interaction with the queue it should re-enable triggering.
An example program that utilises triggering is included at the end of this document. It inserts the contents of the messages it reads into an Oracle table, and demonstrates use of the MQSET call.
Unit of work size
As mentioned earlier in this document it is possible to have many queues and many messages within a unit of work at the same time. As messages and queues are added to the unit of work, the time taken to commit or back out the changes increases. It is therefore prudent to use as small a unit of work size as the application can tolerate.
Obviously, related messages will need to be contained within a single unit of work, in order that all the related changes can be committed or backed out correctly. Applications that only send unrelated messages should try to use a unit of work size of one. That is, each message is committed, or backed out, as its processing is completed.